Background
As a data engineer working with modern cloud platforms like AWS, Azure, and GCP, I’ve seen firsthand how data processing pipelines have grown increasingly distributed and scalable. But with that scale comes complexity — especially when it comes to cost optimization and performance tuning.
One of the key challenges I encountered is with ETL pipelines. These are critical to moving and transforming data, yet they’re often deployed using static, manually selected compute instances, regardless of how heavy or light the workload actually is.
Cloud providers offer Spot Instances at a fraction of the cost of on-demand pricing, but they also come with risks — availability isn’t guaranteed, and sudden interruptions can derail critical jobs. Choosing the right instance based on real-time cost, availability, and pipeline needs is often left to guesswork or outdated defaults.
That’s what motivated me to build a smarter, automated solution — one that could intelligently select infrastructure in real time, reducing both cost and failure rates.
Problem I Wanted to Solve
Here’s what I noticed in existing cloud data systems:
- They rely on manual and fixed instance selections, which don’t adapt to changing workloads.
- They often over-provision, leading to wasted cloud spend.
- Spot instance interruptions cause frequent job failures, especially in dynamic environments.
- It’s hard to scale intelligently across cloud regions and availability zones.
The bottom line: there was no intelligent decision-making in choosing the right compute resource for each job.
So, I set out to solve this with an ML-powered engine that could predict and select the best instance type and region — one that considers workload needs, market prices, and historical behavior.
What I Built (Summary of the Invention)
I designed and prototyped an engine that uses machine learning to automatically select the most cost-efficient and reliable instance type for ETL jobs in the cloud.
Here’s how it works:
- It profiles each ETL job in real time — gathering details like data volume, CPU/memory usage, and execution time.
- It pulls live pricing and availability metrics from cloud APIs (e.g., AWS Spot Advisor).
- It feeds all this into a trained ML model, which predicts:
- The best instance type (like m5.large, r5.2xlarge)
- The optimal region (like us-east-1c)
- Risk of spot instance interruption
- Then it provisions infrastructure using Terraform or AWS SDKs, runs the job, and logs the outcome.
- Over time, the engine learns from job history and continues to improve.
The result? Faster pipelines, fewer failures, and dramatically reduced costs — all without human intervention.
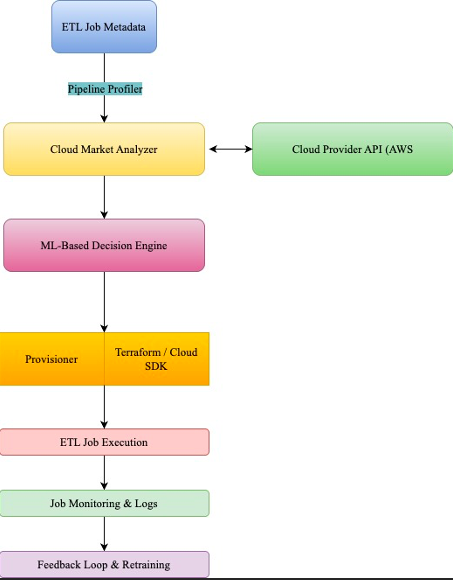
System Components
Here’s the system, broken down:
- Pipeline Profiler: Captures real-time job metadata (CPU, memory, duration, etc.)
- Cloud Market Analyzer: Pulls pricing and availability from cloud APIs
- ML-Based Decision Engine: Predicts optimal instance type and region
- Provisioning Layer: Uses Terraform to spin up/down instances automatically
- Job Executor: Hooks into tools like Airflow or AWS Step Functions to run jobs
- Monitoring & Feedback Loop: Collects outcomes and retrains the model
How It Works (Detailed Flow)
- Profiling the Job: When a pipeline starts, I collect metadata like CPU/memory use, job type, and data size. I log this to a time-series store.
- Checking the Market: The system queries the latest Spot and on-demand pricing across all availability zones, along with interruption rates.
- Making a Decision: The ML model (I used XGBoost in testing) looks at both job and market data to predict the best-fit instance. It also gives a confidence score for stability.
- Provisioning: Once the decision is made, a Terraform plan is executed to provision the right cluster.
- Execution and Monitoring: The pipeline runs, metrics are logged, and outcomes are monitored.
- Learning Over Time: The model is periodically retrained based on job success, cost, runtime, and whether the prediction was accurate.
Real-World Use Cases
Use Case 1: Optimizing Cost for a Daily Spark Job
A team runs a 100GB Spark job on m5.4xlarge costing $1.20/hr. My engine suggested r5.2xlarge at $0.35/hr in a more stable zone.
Result: Same performance, 70% cost savings.
Use Case 2: Real-Time Ingestion via Airflow
An ingestion job triggered every 15 minutes used burst-capable t3.medium instances selected by my system.
Result: 40% latency reduction, 50% less cost.
Use Case 3: Avoiding Outages During Spot Price Surges
When spot prices spiked in us-west-1, the system rerouted to us-east-2, avoiding job failures without any manual intervention.
Result: Zero downtime, seamless rerouting.
This project gave me the chance to merge my skills in data engineering, distributed systems, and cost optimization into something practical — and scalable. I believe it has the potential to help countless teams lower their cloud bills, reduce failures, and simplify pipeline operations.
System Architecture Diagram
About Janardhan Reddy Kasireddy:
Janardhan Reddy Kasireddy is a seasoned Data Engineer and cloud optimization enthusiast with over a decade of experience in distributed systems and big data pipelines. He recently filed a patent for a machine-learning-based ETL instance optimization engine. He enjoys mentoring, writing, and innovating at the intersection of cost efficiency and performance in the cloud.
Contact: LinkedIn
